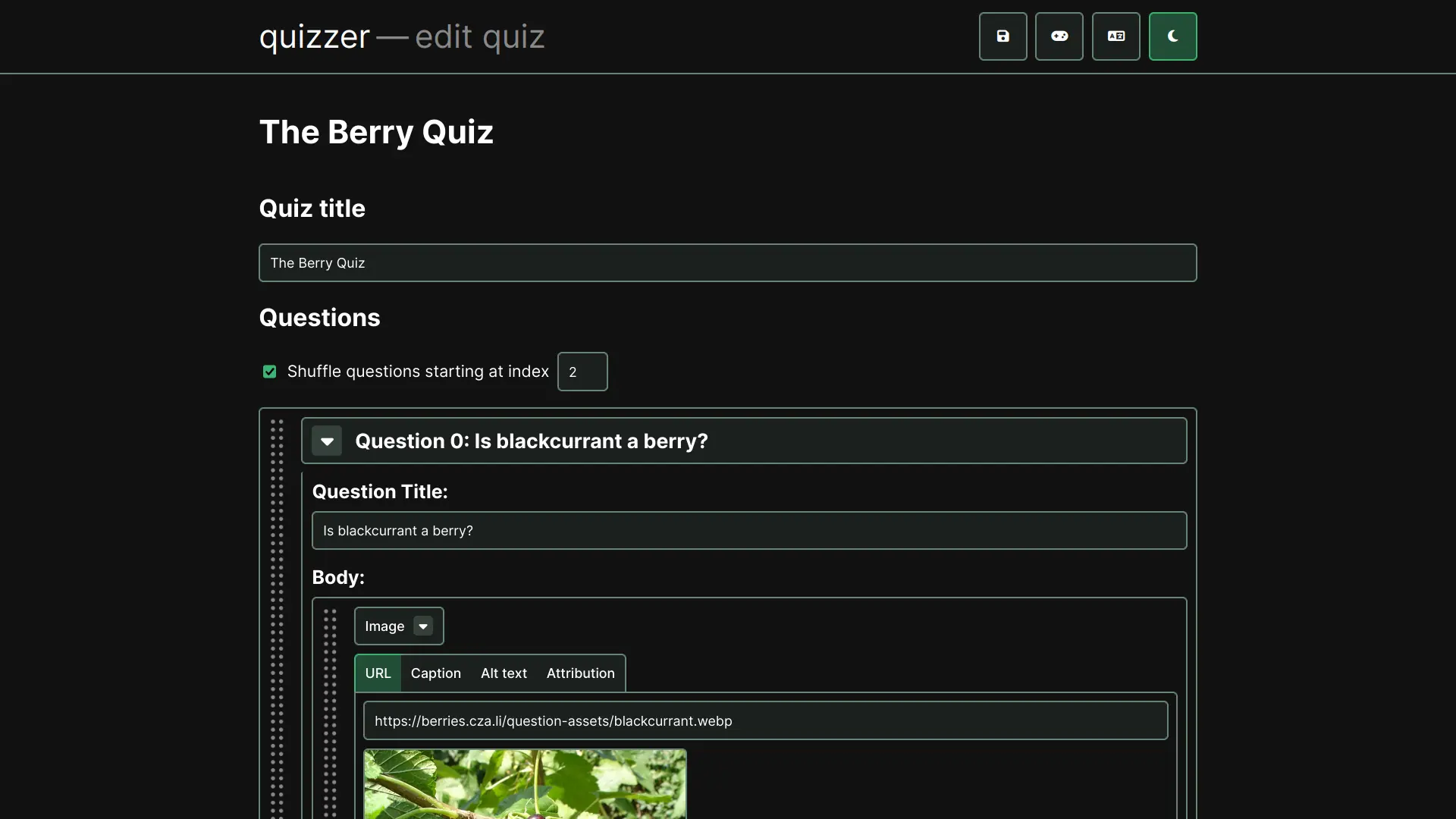
i at some point made a berry quiz to torment my friends with useless knowledge about arbitrary botanical categories, but the original didn't account for fruits that can't neatly be sorted into berry and nonberry.
i'm charlotte, my pronouns are
she and her
, i study an unspecified STEM field in the west of
germany, and make some apps and websites sometimes.
voluntarily, i use (in order of preference):
python, js
involuntarily (in alphabetic order):
bash, c++, java,
php,
typescript
i at some point made a berry quiz to torment my friends with useless knowledge about arbitrary botanical categories, but the original didn't account for fruits that can't neatly be sorted into berry and nonberry.
since i didn't really put much effort into coding it, and the design only really worked for exactly two possible answers, i set out to make an updated version of it, and this time do it properly, with a welldefined json format for quizzes and a seperate interface to edit a quiz.
enter: quizzer. this little thing that i sunk weeks of my life into does all of these things (but in retrospect should have been designed with performance in mind, because loading the berry quiz in the editor takes a little while). however, you can play an updated version of the berry quiz or create your own quiz. I've also abused my own quiz maker to write a poorly written blog post about it, which goes into more detail, and links to its repos and APIs. there are typos in it but you cannot change the quiz that a link points to after the fact.
if you use gnome, you can get the extension on extensions.gnome.org or see the source code
i was pretty annoyed about gnome's default app search
provider ceasing to work if you type one (1)
wrong letter, so i forked someone else's extension
that modified search results and added fuzz.
at first, i used a slightly modified version of the levenshtein edit distance algorithm, but that had a few bugs and was limited to matching queries at the start of words in the result. also, it wouldn't scale well if you had, like, tens of thousands of apps (which you don't). so i switched to pre-indexed matching instead.
basically, the extension looks at every app and
indexes all substrings of a certain length (n-grams) that
the app's fields contain, swapping letters around and
generating abbreviations (both at a
penalty). when you search, your query is also split up into n-grams and
scores can be calculated by how often an app appears
in their index entries. this also takes into account that
n-grams that appear in more apps (like "the") are
likely a lot less interesting than rare ones like,
say, "fox"

mostly as a filler project, i started a little notes app with a simple ui. i did not know how to properly structure python/gtk3 apps back then and added wayyy too much stuff, so the code is a bit of an ugly mess, but it works*!
ok, don't get mad, but there's actually some cool stuff happening under the hood here! if you have js and you're not on the plain html version, that is. i wanted to use web components for a website for a while, and this is that website! then i got annoyed with browser scrolling and, uh, implemented handling for that myself. don't try to break it, because it WILL break.
but yea, you could technically probably build a whole thing with this stuff instead of just my measly landing page and nothing else. i've recently given this page a redesign and that turned out way less painful than i thought!

this is a web app where you can visualise your google takeout data (which the gdpr forces them to give to you). originally, this was a school project (our cs teacher, like seemingly all germans, is obsessed with the topic of internet privacy). it regularly breaks when google changes the format of their takeout archives, so it probably doesn't currently work. nevertheless, you can go to footprint.cza.li to try it.
you can probably smell the redesign here.